NLP, Transformers and LLMs - An Overview
In recent years, breakthroughs in artificial intelligence (AI) have transformed how machines understand and generate human language. This article offers a structured overview of the technologies that made these possible, namely NLP, Transformers, and LLMs, by summarising how they relate, differ, and build upon one another.
At the heart of this evolution lies the Natural Language Processing (NLP), a field that bridges linguistics and computer science. Among its most prominent developments are Transformers, a deep learning architecture that revolutionized language modeling, and Large Language Models (LLMs), such as GPT-4 and Claude. LLMs leverage Transformers to perform a wide range of language tasks with remarkable fluency.

The relationship between NLP, LLMs, and Transformers can be understood as a hierarchy and technological progression:
- NLP is the overarching field - It is a subfield of computer science that has roots in 1950s. It makes it possible for computers to read text, hear speech, interpret it, measure sentiment and determine which parts are important.
- Transformers are a model architecture used in NLP (and beyond, e.g. in vision).
- LLMs are powerful models built with Transformers to perform general-purpose NLP tasks.
What is NLP (Natural Language Processing)?
NLP is a subfield of AI and linguistics focused on the interaction between computers and human (natural) languages. By utilizing various computational operations and analyses, it enables the computers to understand, interpret, generate, and respond to human language in a meaningful way.
Key Components of NLP
- Text Preprocessing: As the first step of processing, the raw input text is typically cleaned and normalized. It consists of:
- Tokenization: Splitting text into words or sentences
- Lowercasing, stemming, lemmatization
- Stop word removal: Removing words like “the”, “is”, “and”
- Part-of-speech tagging
- Syntactic Analysis: Then, the grammatical structure of sentences are analized via:
- Parsing: Analyzing sentence structure
- Dependency parsing: Finding relations between words
- Semantic Analysis: This step is about understanding meaning in the context by utilizing:
- Named Entity Recognition (NER): Identifying people, places, organizations
- Word sense disambiguation: Figuring out word meaning based on context
- Coreference resolution: Resolving “he”, “she”, “it”, etc. to the actual entity
- Discourse & Pragmatic Analysis is about understanding the language beyond individual sentences to handle sarcasm, idioms, or context from previous conversation turns
Common NLP Tasks
- Text classification: Categorize text into predefined classes (e.g., spam detection)
- Named Entity Recognition (NER): Extract structured info (e.g., dates, names) from unstructured text
- Sentiment analysis: Determine the sentiment (positive, negative, neutral)
- Machine translation: Translate text from one language to another
- Summarization: Condense long texts into shorter summaries
- Speech recognition: Convert spoken language into written text
- Question answering: Answer questions based on a passage or corpus
- Chatbots / Conversational Agents: Engage users in natural dialogue
Challenges in NLP
- Ambiguity: Many words/phrases have multiple meanings.
- Context: Long-range dependencies in text
- Bias and Fairness: Models can inherit social biases from training data
- Multilinguality: Languages differ in structure and resource availability
- Real-world noise: Typos, slang, abbreviations, code-mixed languages
As further reading on NLP, this Wikipedia article provides a nice overview of NLP, its history and use cases.
What is a Transformer?
A Transformer is a neural network (NN) architecture designed to handle sequential data. It was introduced in the famous 2017 research paper Attention is All You Need by Vaswani et al. Transformers are the foundation of all major modern language models like BERT, GPT, and T5.
Transformers have revolutionized the NLP and many other AI fields thanks to their following aspects:
- Parallel data processing: Transformers process all tokens simultaneously through a technique called self-attention.
- Global Context: Can attend to the entire input at each layer
- Scalability to large datasets: Easily scales to huge models like GPT-3 or GPT-4
- Versatility: Works for text, code, audio, vision, etc.
The video by 3Blue1Brown below explains the Transformers, the tech behind LLMs:
Key Concepts in Transformers
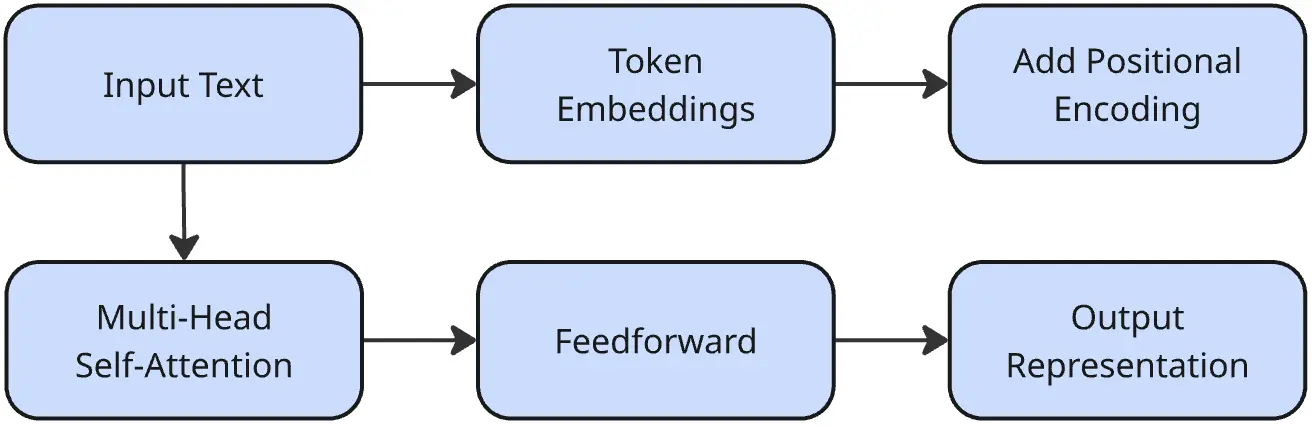
- Self-Attention Mechanism: allows the model to weigh the importance of each word in the input relative to every other word, regardless of distance.
- Positional Encoding: it is added to each token embedding to preserve the word order, since Transformers don’t process tokens sequentially.
- Multi-Head Attention: runs multiple attention mechanisms in parallel to learn different relationships between words simultaneously.
- Layer Normalization and Residual Connections: stabilizes and speeds up the model training.
- Feedforward Layers: after attention, each token passes through dense layers for further processing.
Transformer Architecture: Encoder & Decoder
- Encoder
- Takes the input (e.g., sentence) and converts it into a contextual representation.
- Used in models like BERT, RoBERTa, DistilBERT.
- Decoder
- Takes the encoded input and generates output (e.g., next word).
- Used in models like GPT, GPT-2/3/4.
- Encoder–Decoder
- Combines both parts: encoder processes input, decoder generates output.
- Used in models like T5, BART, Transformer for translation.
Example Transformer Use Cases
- NLP: Translation, Chatbots, Question Answering
- Vision: Object detection (Vision Transformers)
- Biology: Protein folding (AlphaFold)
- Code: Code completion (Codex, Copilot)
Further reading on Transformers: the respective Wikipedia Transformers article.
What are LLMs (Large Language Models)?
LLMs, a subclass of NLP models, are massive neural networks (NNs) trained on vast amounts of text data using the Transformer architecture to understand and generate human language. They can recognize patterns, comprehend context, and produce coherent and relevant responses. They owe their fame to their capability to handle many NLP tasks without task-specific training (called zero-shot/few-shot learning). LLMs are typically defined as:
- Transformer-based models: with hundreds of millions to billions of parameters.
- Pre-trained models: on general very large language data often scraped from the internet.
- This allows them to learn language nuances and patterns at scale.
- The are later fine-tuned for specific tasks or domains.
- Capable of handling multiple tasks: through prompting, few-shot, or zero-shot learning
- Mimicking Human-like Language: LLMs aim to generate text that is indistinguishable from human-written content.
LLM examples
Well-known examples are:
- GPT (Generative Pre-trained Transformer): GPT-4, GPT-3.5 by OpenAI
- T5 (Text-to-Text Transfer Transformer): a series of large language models developed by Google AI
- Claude: AI assistant built by Anthropic
- LLaMA (Large Language Model Meta AI): an open-source LLM developed by Meta
- Mistral: the LLM model developed by Mistral AI
The video by 3Blue1Brown below explains the LLMs:
Further reading on LLMs: the respective Wikipedia Larger Language Model article.